Les protocoles de routage
Introduction aux protocoles de routage
Les exemples de routage présentés jusqu’à présent ne comportaient que quelques routeurs,
où il suffisait de configurer une route statique afin de permettre une communication IP
entre les PC. Par exemple, dans vos exercices, vous avez spécifié un routeur par défaut en
utilisant la commande ip route:
ip route add default via 10.10.0.1
Cette commande ajoute une route IP sur votre PC que tous les datagrammes ayant une
destination qui ne trouve aucune correspondance dans la table de routage doivent être
envoyés à l’adresse 10.10.0.1.
Dans les routeurs FRR, vous utilisez plutôt des commandes du genre
configure terminal
ip route 10.10.0.0/16 10.1.1.1
Cette configuration indique au routeur d'acheminer vers l’adresse 10.1.1.1 les
datagrammes IPv4 dont la destination correspond (match le plus long) avec le préfixe
10.10.0.0/16 .
Contrairement aux laboratoires, les réseaux IP dans les organisations et universités ont un grand nombre de routeurs IP avec une topologie où des liens redondants offrent une meilleur disponibilité du réseau en cas de panne. Configurer manuellement toutes les routes statiques sur tous les routeurs devient rapidement une tâche impossible. Il est donc nécessaire d'avoir recours à des protocoles de routage afin de permettre aux routeurs de découvrir automatiquement les préfixes réseau accessibles, et de calculer les chemins au moindre coût vers ces préfixes.
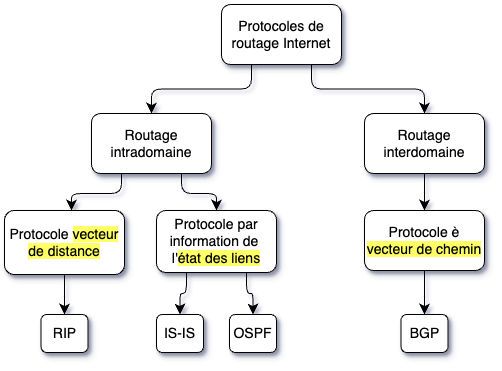
Il existe plusieurs protocoles de routage. Les protocoles de routage sont divisés deux grandes familles:
- Les protocoles de routage intradomaine
- Protocoles utilisés à l'échelle d'une organisation
- La configuration et l'opération du routage est sous la responsabilité d'une organisation
- Les protocoles de routage utilisent un algorithme vecteur de distance (ex: RIP) ou état des liens (ex: OSPF, IS-IS)
- Les protocoles de routage interdomaine
- Protocole utilisé entre les organisations (ex: Internet)
- En date d'aujourd'hui, BGP est le protocole de routage utilisé pour le routage interdomaine.
On utilise aussi intra-AS pour désigner la famille intradomaine, et inter-AS pour interdomaine, où AS signifie Système Autonome (Autonomous System).
Routage intradomaine: État des liens et vecteur de distance
Rappels
Comme présenté en classe, vous savez qu’un réseau peut être représenté par un graphe. Les noeuds du graphe sont les différents hôtes sur internet, que ce soit un routeur ou un ordinateur sur un réseau. Les arêtes du graphe représentent les connexions entre les différents hôtes. Un poids est associé à chacune de ces arêtes. Dans le diagramme suivant, les noeuds sont les routeurs A, B et C, et les arêtes sont les liens qui relient les routeurs, soit les arêtes (A,B), (A,C), et (B,C). Dans cet exemple, le poids (aussi appelé coût) sont c(A,B) = 2, (A,C) = 3, et (B,C) = 2.
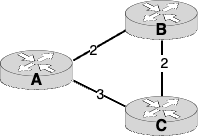
La valeur du poids peut être fixé en fonction de l'implémentation de l’algorithme de routage et de la configuration du protocole de routage. La tâche de déterminer les poids revient à l’administrateur du réseau. Cette tâche peut donc s’avérer la vôtre, et vous aurez à choisir des critères afin de pondérer le poids d’un lien.
L'objectif d'un protocole de routage est de déterminer le chemin au moindre coût pour chaque préfixe réseau connu. Cette tâche est accomplie à l'aide d'un algorithmes de routage. Le coût d'un chemin est déterminé par la somme des poids de chaque lien (arêtes du graph) emprunté pour atteindre la destination (préfixe IP). Lorque le poids des liens sont identiques, le chemin au moindre coût représente alors le chemin le plus court. Si vous avez suivi le cours Algorithmes et structures de données, vous savez qu’il existe une multitude d’algorithmes permettant d’obtenir le plus court chemin entre deux nœuds d’un graphe.
Après avoir déterminer le chemin au moindre coût de chacun des préfixes réseau connus, le protocole de routage est en mesure de peupler la table d'acheminement des routeurs. Ces tables contiennent une association entre un préfixe réseau et l’adresse et interface du prochain saut (next hop). Une fois la table complétée, le plan de commutation du routeur pourra rapidement acheminer les paquets vers la bonne interface de sortie (règle d'acheminement IP selon la correspondance du préfixe le plus long) Si aucune entrée de la table de routage correspond à l’adresse destination du datagramme (ex: pas de route par défaut) le routeur laissera tomber le paquet et envoie une erreur ICMP à l'adresse source de ce paquet.
Les algorithmes de routage intradomaine présentés dans le cadre du cours sont divisés en deux catégories: les algorithmes à vecteur de distances et les algorithmes à état des liens.
Vecteur de distance
Un protocole de routage à vecteur de distance utilise un algorithme dans lequel les routeurs envoient des mises à jour de routage à tous leur voisins directement connectés. Le terme vecteur de distance vient du fait que l'information de routage échangée contient une distance (coût) et une direction (routeur suivant) pour chaque préfixe. Par exemple, "la destination (préfixe) 192.168.0.0/16 se trouve à une distance de 5 dans la direction du voisin X".
Chaque voisin apprend les routes possibles du point de vue de ses voisins, et il annonce à ses voisins sa table de routage avec les vecteurs de distance, soit son propre point de vue. Puisque chaque routeur dépend de l'information reçue de ses voisins, et que ses voisins dépendent aussi de l'information de ses voisins, l'algorithme à vecteur de distance est parfois appelé "routage par rumeurs". L'algorithme à vecteur de distance est un algorithme de routage décentralisé: Aucun routeur n'a une vue complète de la topologie du réseau.
Les algorithmes du type vecteur de distances sont des algorithmes dérivés de Bellman-Ford. L'algorithme utilise un processus itératif où le routeur propage sa table de routage à ses voisins chaque fois qu'un changement survient sur le coût d'un lien, ou lorsqu'une modification de la table de routage survient.
Pour vous rafraichir la mémoire, l’algorithme Bellman-Ford procède comme suit :
- La distance entre le noeud et lui-même est mis à 0.
- Détermine la distance entre le noeud et ses voisins directement connecté est égal au coût du lien vers ce voisin
- Échange ses informations de vecteur de distance avec ses voisins.
- Recalcule ses vecteurs de distance en utilisant les informations reçues de ses voisins
- Si des nouveaux chemins à coût moindre sont calculés, la table de routage est mise à jour, et les vecteurs de distance sont distribués aux voisins
- Le processus boucle jusqu'à ce qu'il n'y ait plus de changement dans la table de routage
La distance est tout simplement un nombre qui peut être ajusté par l'administrateur du réseau. Une implémentation comme RIP utilise 1, ce qui représente donc le nombre de liens à traverser.
Exercice : vecteurs de distance
Soit la topologie réseau suivante :
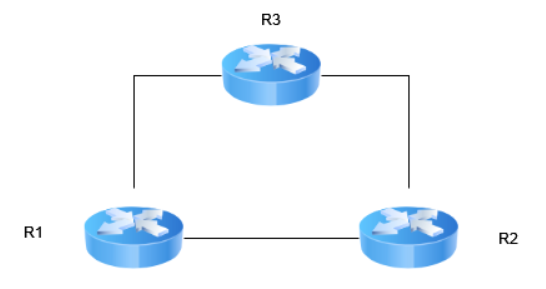
Supposez que le cout des liens est tout simplement 1 pour tous les liens. Quelle est la vitesse de convergence du réseau en nombre d’itérations 1?
Réponse
À l’étape 1, les routeurs mettent à jour l’information dans leur table en fonction de leurs connexions directes à des voisins. La table du routeur R1 est mise à jour comme:
| R1 | R2 | R3 |
|---|---|---|
Donc à partir de R1, la distance vers R2 est et la distance de R1 vers R3 est
Ensuite, R1 partage sa table de routage (vecteurs de distance) à ses voisins, et R1 reçoit l'information de ses voisins R2 et R3.
À l'étape 2, R1 a reçu les informations suivantes de R2 et R3:
- Vecteur de distance reçu de R2: (peut rejoindre R3 à une distance de 1)
- Vecteur de distance reçu de R3: (peut rejoindre R2 à une distance de 1 )
R1 recalcule ses chemins au moindre coût à partir des informations reçues. Le vecteur de distance reçu de R3 indique à R1 qu'il est possible de rejoindre R2 via R3. On utilise l'équation Bellman-Ford pour évaluer le chemin au moindre coût:
Donc aucun changement au vecteur de distance vers R2. L'algorithme donne la même réponse pour la route vers R3: aucun changement.
La table de R1 n’est pas mise à jour puisqu’aucun nouveau chemin n’est plus optimal que ceux déjà présents dans la table. Il n'y a aucune information envoyée aux voisins, et l'algorithme converge après un seul échange de vecteurs de distance.
Exercice : vecteur de distance avec une plus grande topologie
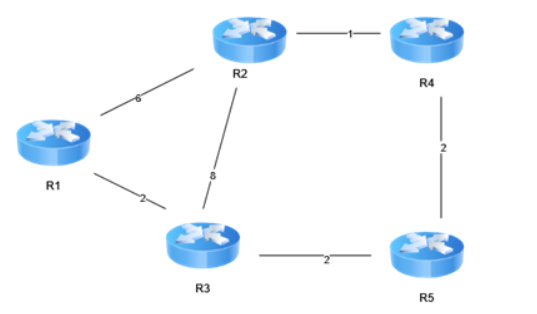
Les couts des liens sont cette fois-ci indiqués sur les liens. À partir de R4, à quoi ressemble la vue d’ensemble de la table de routage aux différentes étapes de la convergence?
Réponse
La table du routeur R4 est présentée pour le corrigé:
R4 est directement connecté à R2 et R5.
| R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|
R2 informe R4 qu’un chemin au cout de 6 peut être emprunté pour communiquer avec R1. R5 informe R4 qu’il peut lui permettre de rejoindre R3 au cout de 2.
| R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|
R5 informe R4 qu’il peut rejoindre R1 au cout de 4.
| R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|
Bien entendu, plusieurs autres mises à jour sont reçues par R4. La table de routage de R4 sera modifiée seulement lorsqu'un nouveau chemin au moindre coût sera trouvé.
Aussi, les mises à jour sont ici présentées comme synchronisées. Or, dans la vraie vie, elles ne le sont pas du tout. En plus du fait que les routeurs ne calculent pas tous des tables de routage à la même vitesse (certains ont des processeurs plus puissants, par exemple), les annonces de nouvelles tables de routage ont des temps de transit différents !
Exercice : problèmes avec les algorithmes à vecteur de distance
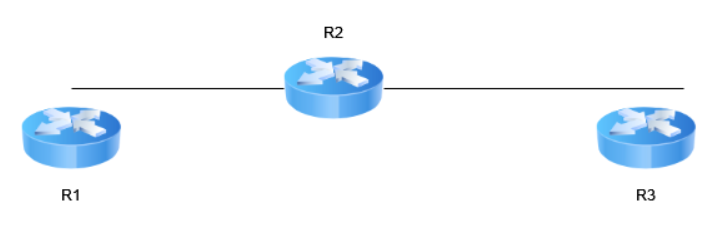
À quoi ressemble la vue d’ensemble de la table de routage lorsqu’un algorithme à vecteur de distance a convergé ? Supposez que le cout des liens est toujours unitaire (toujours 1).
Que se passe-t-il lorsque le lien entre R2 et R3 tombe en panne ? Supposez que R2 trouve un moyen de s’en rendre compte. Comment R2 met-il à jour sa table ? Vous réussirez mieux cet exercice en laissant votre pensée logique de côté et en pensant comme un routeur. Un routeur qui ne voit que les tables de routage annoncées par ses voisins.
Réponse
Initialement, la table de routage de R2 ressemble à :
| R1 | R2 | R3 |
|---|---|---|
Lorsque R3 tombe en panne, R2 devrait tout simplement annoncer à R1 qu’il est maintenant impossible de rejoindre R3. Or, R2 voit présentement que R1 fournit bel et bien un chemin vers R3, annoncé à un cout de 2 !
R2 mettra donc à jour sa table de routage et y inclura qu’il peut rejoindre R3 à un cout de 3.
| R1 | R2 | R3 |
|---|---|---|
Lorsqu’il partagera cette information à ses voisins, R1 mettra sa table à jour et annoncera qu’il peut rejoindre R3 pour un cout de 4... et ainsi de suite ! Problème...
L’exercice précédent vous a permis de réaliser une faille des algorithmes à vecteur de distance, où les routeurs n'ont pas de vue globale de la topologie. Une solution sera présentée pour les algorithmes de routage qui utilisent Bellman-Ford (ou une solution dérivée). En attendant, je vous suggère d’y réfléchir...
Exercice : éviter le compte à l’infini
Comment serait-il possible d’éviter une situation de compte à l’infini ?
Réponse
Les mécanismes suivants sont ajoutés dans les implémentations de protocoles de routage à vecteur de distance comme RIP:
- Split Horizon : Un routeur A qui utilise le routeur B pour se rendre au routeur C ne transmets pas cette information de routage à B. En effet, B est bien mieux qualifié pour tenir un état à jour des routes pour se rendre à C.
- Reverse poison : Un routeur A qui utilise le routeur B pour se rendre au routeur C annonce une distance infinie vers C au routeur B. Ceci évite que B utilise A comme prochain saut pour rejoindre C.
États des liens
Un protocole à vecteur de distance utilise l'information partagée par ses voisins directs, et indique une direction avec une distance. L'analogie est un panneau de signalisation routier où on vous indique une direction avec la distance à parcourir en kilomètre. Les protocoles à état des liens ont une vue globale de la topologie. Pour reprendre l'analogie de l'information routière, les protocoles à état des liens possèdent une carte routière, et donc une vue globale.
C'est une différence importante entre ces deux protocoles: Dans un protocole de routage à état des liens, l'information de la topologie doit être propagée dans tous les routeurs.
Les protocoles à état des liens utilisent typiquement un algorithme dérivé de celui de Dijkstra afin de calculer le plus court chemin vers tous les autres nœuds de la topologie. Aucun exercice ne sera fourni sur le calcul de chemins par Dijkstra puisqu’il est assumé que vous en avez amplement réalisé dans votre cours Algorithme et structures de données. Ce dont il faut tout de même se rappeler, c’est que le routeur doit trouver une manière d’obtenir le graphe de la topologie en premier lieu !
Commençons par présenter directement la différence entre les deux classes d’algorithmes : alors que les algorithmes à vecteurs de distance partagent leur vue complète des chemins au moindre coût à leurs voisins directement connectés seulement, les algorithmes à état des liens ne partagent que l’information sur leurs liens et voisins directement connectée, mais à tous les routeurs dans la topologie.
Chaque routeur vient tout de même à posséder l’entièreté de la topologie lorsqu’il calcule la plus courte distance vers une certaine destination. Mais comment obtenir une vue complète de la topologie ?
Vous avez probablement remarqué que les algorithmes de routage présentés jusqu’à présent sont des algorithmes distribués. Il n’existe pas d’entité supérieure ayant une vue d’ensemble sur le réseau et utilisant cette information pour router les paquets. Puisque l’algorithme est distribué, il n’y a pas d’autorité. Il faut donc s’assurer que tous les membres de la topologie sont de bons citoyens et contribuent à l’effort commun de router les paquets de manières optimales.
Cette section explore l’une des grandes difficultés liées aux protocoles à état des liens, soit comment propager l’information à toute la topologie en s’assurant que tous les routeurs contribuent optimalement à la construction du plan de routage.
Afin d’obtenir une garantie que tous les routeurs obtiendront l’information nécessaire, un algorithme à état des liens inonde le réseau de « paquets »2 contenant les données de chaque routeur et l'information de ses liens. Le principe d’inonder le réseau est assez simple: chaque routeur envoie l’information sur l’état de ses liens à ses voisins. Lorsqu’un routeur reçoit l’état des liens d’un voisin, il fait suivre l’information à ses autres voisins.
L’inondation du réseau est intéressante puisque les routeurs recevront tous l’information à un moment ou un autre. Plus encore, cette information arrivera rapidement puisque les routeurs n’ont pas besoin de recalculer leur table de routage avant de faire suivre l’information (contrairement aux algorithmes à vecteur de distance). Cependant, propager l’information de cette manière n’est pas sans problème.
En reprenant la topologie à 5 routeurs introduite plus haut :
Ici, R1 ne pourra apprendre sur les liens de R4 directement. Le message devra être relayé par R2 ou tout autre routeur.
Ensuite, puisqu’il existe plusieurs chemins possible pour recevoir l’information, un routeur peut recevoir plus d’une copie d'une information d'état de liens d'un routeur distant. Par exemple, R1 peut recevoir l’information de l'état des liens de R4 des sources suivantes (dans un ordre probablement similaire si le cout a été choisi judicieusement) :
- Par R3 via le chemin R4-R5-R3-R1.
- Par R2 via le chemin R4-R2-R1.
- Par R3 via le chemin R4-R2-R3-R1 ?
- Par R2 via le chemin R4-R5-R3-R2-R1 ???
Certains de ces messages sont dupliqués et ne devraient probablement pas être suivis. Aussi, qu’arrive-t-il si l’état des liens de R4 change subitement après la transmission du premier état des liens ?
Exercice : problèmes d’inondation
Qu’arrive-t-il si l’état des liens change subitement après la transmission du premier état des liens ? Supposez que R2 et R5 ont tous les deux reçu l’information, mais ne l’ont pas encore propagée.
Réponse
Voici un exemple de ce qui pourrait arriver. Aucune synchronisation n’est réellement garantie. Cependant, lors du design d’un algorithme, il s’avère judicieux de penser en termes du pire cas. Voici donc un exemple d’une situation assez désagréable qui pourrait survenir.
En supposant que les couts sont judicieusement choisis, le nouveau chemin annoncé par R4 arrivera le plus rapidement à R1 par le chemin R4-R5-R3-R1. Ce chemin est plus court que le plus long chemin R4-R5-R3-R2-R1. Il est donc possible que la table de R1 utilise temporairement de l’information qui n’est pas à jour. En effet :
- R1 reçoit le premier message de R4 via R4-R5-R3-R1. Il met à jour sa table (ok).
- R1 reçoit le deuxième message de R4 via R4-R5-R3-R1. Il met à jour sa table (ok).
- R1 reçoit le premier message de R4 via R4-R5-R3-R2-R1. Il met à jour sa table (en retard).
- R1 reçoit le deuxième message de R4 via R4-R5-R3-R2-R1. Il met à jour sa table (ok).
Nécessité d’un numéro de séquence
En plus de contenir l’information sur le routeur et ses liens, les messages d’état des liens contiennent aussi les informations suivantes:
- Un identifiant du noeud à l'origine du message.
- Un numéro de séquence.
- Un « âge ».
Le numéro de séquence et l’âge du message permettent aux routeurs détecter les messages dupluqués et déterminer quel message contient l’état des liens le plus à jour d'un routeur. Cela permet donc d’éviter le problème soulevé à l’exercice précédent. Nous allons voir que l'utilisation de numéro de séquence est aussi utilisé dans le protocole TCP pour mettre en oeuvre une transmission fiable des données.
Différence entre les deux types de protocoles
Bien qu’il soit possible de comparer la mémoire, la quantité de messages et le temps de calcul utilisés par chacun des algorithmes, nous préférons seulement souligner la différence au niveau de la vitesse de convergence.
Exercice : vitesse de convergence
Laquelle des deux classes d’algorithmes converge le plus rapidement selon vous ?
Réponse
Les algorithmes à état des liens convergent plus rapidement que les algorithmes à vecteur de distance. Sans compter les boucles potentielles dans les algorithmes à vecteur de distance, la nécessité de recalculer la table de routage avant de partager une mise à jour impacte la vitesse de convergence de ce protocole.
Routage interdomaine: Un réseau de réseaux
Bien qu’il n’y ait pas de point central exact à Internet, le réseau n’est pas non plus complètement décentralisé. Les paquets que vous envoyez à partir de votre poste sont d’abord acheminés dans votre réseau local jusqu’à rejoindre votre fournisseur de service internet (FSI). Si le paquet est destiné à un autre abonné du même FSI, il est probable que ce paquet se rende directement au réseau local de votre destination à partir de votre FSI. En effet, il n’est pas trop farfelu d’assumer que votre fournisseur de service est en mesure de rejoindre ses clients !
Cependant, si le paquet est acheminé vers une destination plus éloignée, elle ne sera pas nécessairement desservie par le même fournisseur. Comment les routeurs de votre fournisseur réussissent-ils à acheminer votre paquet vers sa destination ?
Les fournisseurs de service doivent être connectés entre eux d’une manière ou d’une autre. C’est dans ce sens qu’Internet est un réseau de réseaux. Votre réseau local à la maison est un réseau. Les différents clients de votre FSI ainsi que les routeurs qui les desservent forme un réseau. Les différents fournisseurs de service internet connectés entre eux forment un réseau ! C’est ça, Internet avec un grand « I ».
Exercice : Fournisseur de services internet
Savez-vous quel est votre FSI ? Comment pourriez-vous l’obtenir ?
Réponse
Des services comme ipinfo.io permettent d’obtenir votre adresse IP
publique. Vous pouvez aussi utiliser une application comme traceroute pour obtenir la
liste des différents routeurs traversés pour rejoindre une certaine adresse. À partir de
votre adresse publique, vous pouvez utiliser une application comme whois pour identifier
votre fournisseur de service.
On peut comprendre qu’avec la taille actuelle d’Internet, si un protocole de routage état des liens tel qu’OSPF serait problématique:
- Tous les routeurs sur Internet aurait la visibilité de tous les liens. Maintenir une stabilité serait très difficile.
- Sécurité serait difficile contre des attaques malicieuses ou même des erreurs humaines.
- Un protocole de routage à état des liens demande une distribution de l’information des liens entre tous les routeurs. Requis pratiquement impossible aujourd'hui à l’échelle d’Internet.
Un changement de topologie à un endroit provoque un échange d’information entre tous les routeurs, qui doivent également recalculer leurs tables d’acheminement. La croissance du réseau augmentera la quantité de changements de topologies, provoquant une surcharge sur tous les routeurs. La croissance du réseau est aussi accompagné par l’augmentation des organisations qui sont connectés, et la quantité d’administrateurs réseau qui doivent se coordonner pour des mises à jour et autre modifications nécessaire au réseau.
Dans le but de supporter le routage IP à l'échelle d'Internet, le protocole de routage interdomaine introduit une hiérarchie dans l'architecture des réseaux: Les réseaux d'une organisation sont regroupés sous une entité appelé système autonome, et le routage interdomaine est effectué entre des systèmes autonomes.
Les systèmes autonomes
Un système autonome (AS pour autonomous system) est un regroupement d’appareils fournissant des politiques de routage similaires. Un système autonome est responsable d’un ou plusieurs préfixes réseaux et est responsable d'acheminer les paquets destinés aux adresses de ce préfixe. Les systèmes autonomes sont identifiés à partir d’un entier de 16 ou 32 bits. Le réseau constitué des différents appareils de votre fournisseur de service forme un système autonome. Cependant, ce ne sont pas que les FSI qui opèrent les AS. De grosses compagnies, des universités ainsi que des institutions gouvernementales peuvent aussi gérer un système autonome.
Ces systèmes autonomes constituent une partie des réseaux inclus dans le réseau de réseaux qu’est Internet. Différents AS sont connectés entre eux. Certains offrent même la possibilité d'acheminer du trafic provenant de l’extérieur de leur système.
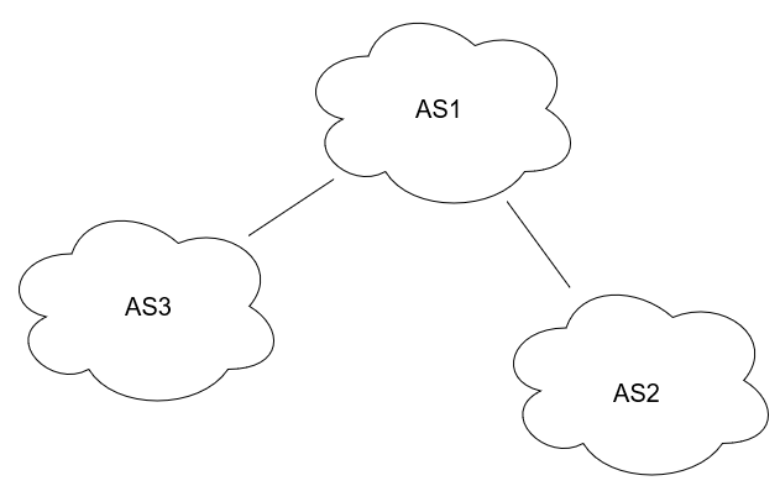
Exercice : AS traversés pour rejoindre google.com
Combien de systèmes autonomes sont traversés pour rejoindre les serveurs de google.com à partir de votre poste ?
La commande traceroute possède un drapeau lui mentionnant de lister les AS traversés.
Par exemple, l’AS1 pourrait router les paquets provenant de l’AS2 vers l’AS3. Ce genre de politique de routage provient de négociations entre les opérateurs des AS. Deux fournisseurs de service pourraient s’entendre pour router les paquets provenant de l’autre fournisseur en échange que celui-ci fasse de même.
Réponse
Plusieurs bonnes réponses possibles. Notez les différents numéros d’AS traversés. Remarquez aussi que le numéro d’AS reste parfois le même d’un routeur à l’autre. Pourquoi est-ce le cas ?
Réponse : Parce que votre traceroute circulait à l’intérieur d’un AS.
Les types de systèmes autonomes
- stub : Un système autonome de type stub n’est connecté qu’à un autre système autonome. Il se fie donc entièrement à l’autre système pour router tous ses paquets. Une universit�é pourrait opérer un système autonome, mais n’être connectée qu’à un seul fournisseur de service.
- multihomed : Les AS multihomed sont connectés à Internet via au moins 2 autres AS. Des fournisseurs de service sont souvent connectés à plusieurs autres fournisseurs afin de router les paquets aussi efficacement que possible. Ce genre de configuration fourni aussi des liens alternatifs si l’un d’entre eux venait à tomber
- transit : Ce sont des AS qui routent le trafic en provenance et en destination d’autres systèmes autonomes.
Il existe un autre type d’AS qui n’est pas présenté dans le cadre du cours, soit les points d’échange (IX).
À l'intérieur d'un système autonome
Les systèmes autonomes ne sont pas que des nuages comme ceux présentés dans la figure précédente ! Ils contiennent plusieurs routeurs interconnectés et opérants selon une politique de routage commune.
Par politique de routage commune, nous voulons ici dire que tous les routeurs sont configurés et opérés par une organisation. Puisque le routage se fait à l’intérieur de l’AS, les protocoles utilisés sont dits intra-AS.
Cependant, nous avons aussi vu que les systèmes autonomes sont connectés et capables de communiquer entre eux. Il faut donc aussi un protocole permettant de calculer et partager les chemins optimaux pour faire circuler les données l’un AS à l’autre ! Puisqu’ils permettent de lier les différents AS, ces protocoles sont dits inter-AS.
Ce ne sont pas tous les routeurs dans un AS qui ont un accès direct aux autres systèmes autonomes. Certains routeurs sont configurés comme routeur de frontière. Ce sont sur ces routeurs que les protocoles inter-AS sont implémentés. Si un autre routeur veut envoyer un paquet vers un AS qui n’est pas le sien, il doit acheminer ce paquet vers le routeur de frontière.
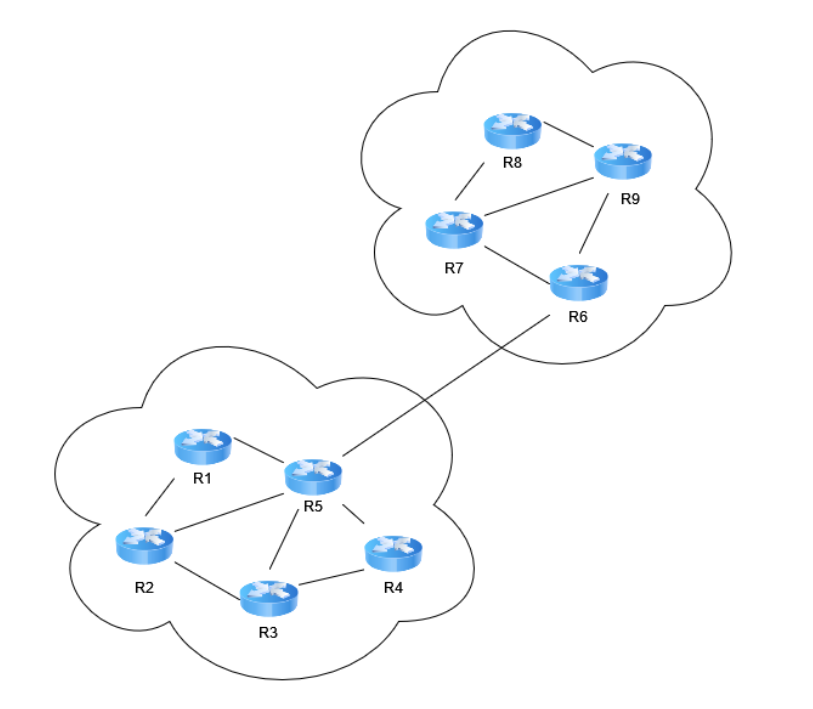
Exercice : Types de protocoles de routage
Des routeurs présentés à la figure précédente, lesquels utilisent des protocoles de routage inter-AS ? Lesquels utilisent des protocoles de routage intra-AS ?
Réponse
Tous les routeurs utilisent un protocole de routage intra-AS. Seuls les routeurs de frontière (les routeurs R5 et R6) implémentent un protocole de routage inter-AS.
Exercice : Communication inter-AS
Le routeur R2 tente de rejoindre le routeur R8. Il doit donc envoyer des paquets vers un autre AS. Quel type de protocole de routage lui permettra de trouver le routeur de frontière ?
Réponse
Un protocole de routage intra-AS. En effet, c’est le routeur R5 qu’il doit rejoindre. Le routeur de frontière fait partie du même AS !
Exercice : Information dans les tables de routage
Le routeur R1 reçoit-il de l’information de la part du routeur R8 lorsqu’il construit sa table de routage ? Qu’en est-il de R5 ? Reçoit-il de l’information de la part de R8 lorsqu’il construit sa table de routage ?
Réponse
Non, le routeur R1 ne reçoit pas d’information de la part de R8 lorsqu’il construit sa table de routage. R1 est dans un AS différent de R8, et n’implémente pas de protocole de routage inter-AS.
Non, le routeur R5 ne reçoit pas d’information de la part de R8 lorsqu’il construit sa table de routage. Bien que R5 soit un routeur de frontière, ce n’est qu’avec R6 qu’il échange de l’information lorsqu’il construit sa table de routage inter-AS.